What is the best way to list all the children in AEM?
Stream-based VS page.listChildren VS Query Builder
Introduction:
AEM Sling Query is a resource traversal tool recommended for content traversal in AEM. Traversal using listChildren(), getChildren(), or the Resource API is preferable to writing JCR Queries as querying can be more costly than traversal. Sling Query is not a replacement for JCR Queries. When traversal involves checking multiple levels down, Sling Query is recommended because it involves lazy evaluation of query results.
JCR queries in AEM development and recommends using them sparingly in production environments due to performance concerns. JCR queries are suitable for end-user searches and structured content retrieval but should not be used for rendering requests such as navigation or content counts.
How can I get all the child pages in AEM using JCR Query?
List<String> queryList = new ArrayList<>();
Map<String, String> map = new HashMap<>();
map.put("path", resource.getPath());
map.put("type", "cq:PageContent");
map.put("p.limit", "-1");
Session session = resolver.adaptTo(Session.class);
Query query = queryBuilder.createQuery(PredicateGroup.create(map), session);
SearchResult result = query.getResult();
ResourceResolver leakingResourceResolverReference = null;
try {
for (final Hit hit : result.getHits()) {
if (leakingResourceResolverReference == null) {
leakingResourceResolverReference = hit.getResource().getResourceResolver();
}
queryList.add(hit.getPath());
}
} catch (RepositoryException e) {
log.error("Error collecting inherited section search results", e);
} finally {
if (leakingResourceResolverReference != null) {
leakingResourceResolverReference.close();
}
}
But JCR Query consumes more resources
AEM recommends using Page.listchildren because of less complexity
AEM Schedulers are commonly used to run bulk tasks at an off time (nonbusiness hours) and some tasks are run periodically to fetch results cached and fetched by the front end.
How can we make sure bulk tasks won’t impact AEM performance (CPU or Heap memory) / throttle the system?
Introduction:
In Computer Software, Scheduling is a paradigm of planning for the execution of a task at a certain point in time and it can be broadly classified into two types:
1. Scheduled Task – executing once at a particular future point in time
2. Frequent scheduling – repeat periodically at a fixed interval
The use case for the scheduler:
1. Sitemap generation
2. Synching product data from AEM Commerce
3. Fetch DB content and place it in the repository to be picked up by frontend and in turn cached in Dispatcher
4. Fetch Stats or reports and place them in the repository to be picked up by frontend and in turn cached in Dispatcher
ACS Commons Throttled Task Runner is built on Java management API for managing and monitoring the Java VM and can be used to pause tasks and terminate the tasks based on stats.
Throttled Task Runner (a managed thread pool) provides a convenient way to run many AEM-specific activities in bulk it basically checks for the Throttled Task Runner bean and gets current running stats of the actual work being done.
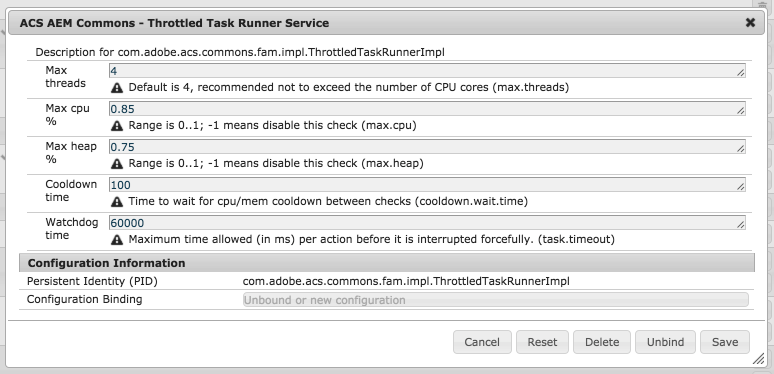
OSGi Configuration:
The Throttled Task Runner is OSGi configurable, but please note that changing configuration while work is being processed results in resetting the worker pool and can lose active work.
Throttled task runner OSGi
Max threads: Recommended not to exceed the number of CPU cores. Default 4.
Max CPU %: Used to throttle activity when CPU exceeds this amount. Range is 0..1; -1 means disable this check.
Max Heap %: Used to throttle activity when heap usage exceeds this amount. Range is 0..1; -1 means disable this check.
Cooldown time: Time to wait for CPU/MEM cooldown between throttle checks (in milliseconds)
Watchdog time: Maximum time allowed (in ms) per action before it is interrupted forcefully.
JMX MBeans
Throttled Task Runner MBean
This is the core worker pool. All action managers share the same task runner pool, at least in the current implementation. The task runner can be paused or halted entirely, throwing out any unfinished work.
Retry posting the data at least some time until the response is 200
Retry any OAK operations, when the exception occurs
Introduction:
Usually, with respect to AEM, we don’t have Retry Utils which can retry the particular operation whenever an exception occurred.
If we are doing multiple transactions on the AEM repository, especially on a particular node like updating properties or updating references, the OAK operation would through exceptions like your operation is blocked by another operation or invalid modification.
If we are connecting to external services through REST API and the connection has failed or timeout and if we want to connect to the external system then we don’t have the option to retry out of the box
Create a Retry Utils as shown below:
Retry on Exception:
package com.test.utils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class RetryOnException {
private static final Logger log = LoggerFactory.getLogger(RetryOnException.class);
public static interface CallToRetry {
void process() throws Exception;
}
public static boolean withRetry(int maxTimes, long intervalWait, CallToRetry call) throws Exception {
if (maxTimes <= 0) {
throw new IllegalArgumentException("Must run at least one time");
}
if (intervalWait <= 0) {
throw new IllegalArgumentException("Initial wait must be at least 1");
}
Exception thrown = null;
for (int counter = 0; counter < maxTimes; counter++) {
try {
call.process();
return true;
} catch (Exception e) {
thrown = e;
log.info("Encountered failure on {} due to {}, attempt retry {} of {}", call.getClass().getName() , e.getMessage(), (counter + 1), maxTimes, e);
}
try {
Thread.sleep(intervalWait);
} catch (InterruptedException wakeAndAbort) {
break;
}
}
throw thrown;
}
}
The above Util can be used in any code as shown below and the retry will happen only when the exception occurs during operations
package com.test.utils;
import java.util.concurrent.atomic.AtomicInteger;
import org.aarp.www.mcp.utils.RetryOnException;
public class ExampleOne {
public static void main(String[] args) {
AtomicInteger atomicCounter = new AtomicInteger(0);
try {
RetryOnException.withRetry(3, 500, () -> {
if(atomicCounter.getAndIncrement() < 2) {
System.out.println("Retring count with Exception" + atomicCounter.get());
throw new Exception("Throwing New Exception to test");
} else {
System.out.println("Retring count without Exception " + atomicCounter.get());
}
});
} catch (Exception e) {
e.printStackTrace();
}
}
}
Exception Result
Retry on the condition:
package com.test.utils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class RetryOnCondition {
private static final Logger log = LoggerFactory.getLogger(RetryOnCondition.class);
public static interface CallToRetry {
boolean process() throws Exception;
}
public static boolean withRetry(int maxTimes, long intervalWait, CallToRetry call) throws Exception {
if (maxTimes <= 0) {
throw new IllegalArgumentException("Must run at least one time");
}
if (intervalWait <= 0) {
throw new IllegalArgumentException("Initial wait must be at least 1");
}
Exception thrown = null;
for (int counter = 0; counter < maxTimes; counter++) {
try {
boolean status = call.process();
if(status) {
return true;
}
} catch (Exception e) {
thrown = e;
log.info("Encountered failure on {} due to {}, attempt retry {} of {}", call.getClass().getName() , e.getMessage(), (counter + 1), maxTimes, e);
}
try {
Thread.sleep(intervalWait);
} catch (InterruptedException wakeAndAbort) {
break;
}
}
throw thrown;
}
}
The above Util can be used to retry based on the condition like if the connection is successful or the response code is 200
How to Bulk Add, Update or remove page properties in AEM? Without using the Groovy console.
Requirement:
Create a reusable process that can be used to search for the pages based on resourceType and do the CRUD operations on the results.
Introduction:
Usually, whenever we are using editable templates, we might have some initial content but for some reason, if we want to update the experience fragment path or some page properties then usually, we go for Groovy script to run bulk update.
But AMS don’t install developer tools on the PROD, we need to go to other options and for the above requirement, we can use MCP.
MCP (Manage Controlled Processes) is both a dashboard for performing complex tasks and a rich API for defining these tasks as process definitions. In addition to kicking off new processes, users can also monitor running tasks, retrieve information about completed tasks, halt work, and so on.
Add the following maven dependency to your pom to extend MCP
Create Process Definition factory – PropertyUpdateFactory
This class tells ACS Commons MCP to pick the process definition and process name getName and you need to mention the implementation class inside the createProcessDefinitionInstance method as shown below:
package com.mysite.mcp.process;
import org.osgi.service.component.annotations.Component;
import com.adobe.acs.commons.mcp.ProcessDefinitionFactory;
@Component(service = ProcessDefinitionFactory.class, immediate = true)
public class PropertyUpdateFactory extends ProcessDefinitionFactory<PropertyUpdater> {
@Override
public String getName() {
return "Property Updator";
}
@Override
protected PropertyUpdater createProcessDefinitionInstance() {
return new PropertyUpdater();
}
}
Create Process Definition implementation – PropertyUpdater
This is an implementation class where we are defining all the form fields required for the process to run
How to use java streams in AEM? Can I use streams for iterating and resources?
Requirement:
Use Java streams to iterate child nodes, validating and resources and API’s.
Introduction:
There are a lot of benefits to using streams in Java, such as the ability to write functions at a more abstract level which can reduce code bugs, compact functions into fewer and more readable lines of code, and the ease they offer for parallelization
Streams have a strong affinity with functions
Streams encourage less mutability
Streams encourage looser coupling
Streams can succinctly express quite sophisticated behavior
Streams provide scope for future efficiency gains
Java Objects:
This class consists of static utility methods for operating on objects. These utilities include null-safe or null-tolerant methods for computing the hash code of an object, returning a string for an object, and comparing two objects.
if (Objects.nonNull(resource)) {
resource.getValueMap().get("myproperty", StringUtils.EMPTY);
}
Java Optional:
Trying using Java Optional util, which is a box type that holds a reference to another object.
Is immutable and non serializable ant there is no public constructor and can only be present or absent
It is created by the of(), ofNullable(), empty() static method.
In the below example Optional resource is created and you can check whether the resource is present and if present then get the valuemap
Optional < Resource > res = Optional.ofNullable(resource);
if (res.isPresent()) {
res.get().getValueMap().get("myproperty", StringUtils.EMPTY);
}
you can also call stream to get children’s as shown below:
Optional < Resource > res = Optional.ofNullable(resource);
if (res.isPresent()) {
List < Resource > jam = res.stream().filter(Objects::nonNull).collect(Collectors.toList());
}
Java Stream Support:
Low-level utility methods for creating and manipulating streams. This class is mostly for library writers presenting stream views of data structures; most static stream methods intended for end users are in the various Stream classes.
In the below example we are trying to get a resource iterator to get all the child resources and map the resources to a page and filter using Objects and finally collect the list of pages.
We can also adapt the resource to Page API and call the listchilderens to get all the children and using stream support we are going to map the page paths into a list as shown below:
No, we can also use Content Fragment and other API’s as well for example in the below code we are trying to iterate contentfragment and get all the variations of the contentfragment.
Can Java Streams and Resource Filter be used as an alternative to Query Builder queries in AEM for filtering pages and resources based on specific criteria?
Requirement:
The query for the pages whose resurcetype = “wknd/components/page” and get child resources which have an Image component (“wknd/components/image”) and get the file reference properties into a list
Query builder query would be like this:
@PostConstruct
private void initModel() {
Map < String, String > map = new HashMap < > ();
map.put("path", resource.getPath());
map.put("property", "jcr:primaryType");
map.put("property.value", "wknd/components/page");
PredicateGroup predicateGroup = PredicateGroup.create(map);
QueryBuilder queryBuilder = resourceResolver.adaptTo(QueryBuilder.class);
Query query = queryBuilder.createQuery(predicateGroup, resourceResolver.adaptTo(Session.class));
SearchResult result = query.getResult();
List < String > imagePath = new ArrayList < > ();
try {
for (final Hit hit: result.getHits()) {
Resource resultResource = hit.getResource();
@NotNull
Iterator < Resource > children = resultResource.listChildren();
while (children.hasNext()) {
final Resource child = children.next();
if (StringUtils.equalsIgnoreCase(child.getResourceType(), "wknd/components/image")) {
Image image = modelFactory.getModelFromWrappedRequest(request, child, Image.class);
imagePath.add(image.getFileReference());
}
}
}
} catch (RepositoryException e) {
LOGGER.error("error occurered while getting result resource {}", e.getMessage());
}
}
Introduction
This article discusses the use of Java Streams and Resource Filter in optimizing AEM Query Builder queries. The article provides code examples for using Resource Filter Streams to filter pages and resources and using Java Streams to filter and map child resources based on specific criteria. The article also provides optimization strategies for AEM tree traversal to reduce memory consumption and improve performance.
Resource Filter bundle provides a number of services and utilities to identify and filter resources in a resource tree.
Resource Filter Stream:
ResourceFilterStream combines the ResourceStream functionality with the ResourcePredicates service to provide an ability to define a Stream<Resource> that follows specific child pages and looks for specific Resources as defined by the resources filter script. The ResourceStreamFilter is accessed by adaptation.
The ResourceFilter and ResourceFilteStream can have key-value pairs added so that the values may be used as part of the script resolution. Parameters are accessed by using the dollar sign ‘$’
Similar to indexing in a query there are strategies that you can do within a tree traversal so that traversals can be done in an efficient manner across a large number of resources. The following strategies will assist in traversal optimization.
Limit traversal paths
In a naive implementation of a tree traversal, the traversal occurs across all nodes in the tree regardless of the ability of the tree structure to support the nodes that are being looked for. An example of this is a tree of Page resources that has a child node of jcr:content which contains a subtree of data to define the page structure. If the jcr:content node is not capable of having a child resource of type Page and the goal of the traversal is to identify Page resources that match specific criteria then the traversal of the jcr:content node can not lead to additional matches. Using this knowledge of the resource structure, you can improve performance by adding a branch selector that prevents the traversal from proceeding down a nonproductive path
Limit memory consumption
The instantiation of a Resource object from the underlying ResourceResolver is a nontrivial consumption of memory. When the focus of a tree traversal is obtaining information from thousands of Resources, an effective method is to extract the information as part of the stream processing or utilize the forEach method of the ResourceStream object which allows the resource to be garbage collected in an efficient manner.
How can I iterate child nodes and get certain properties? Specifically, the requirement is to get child resources of the current resource and get all image component file reference properties into a list.
Requirement:
Get child resources of the current resource and get all image component file reference properties into a list
Can I use Java 8 Streams?
Introduction: Using while or for loop:
@PostConstruct
private void initModel() {
List < String > imagePath = new ArrayList < > ();
Iterator < Resource > children = resource.listChildren();
while (children.hasNext()) {
final Resource child = children.next();
if (StringUtils.equalsIgnoreCase(child.getResourceType(), "wknd/components/image")) {
Image image = modelFactory.getModelFromWrappedRequest(request, child, Image.class);
imagePath.add(image.getFileReference());
}
}
}
Introduction Abstract Resource Visitor:
Sling provides AbstractResourceVisitor API, which performs traversal through a resource tree, which helps in getting child properties.
Create the class which extends AbstractResourceVisitor abstract class
Override accept, traverseChildren and visit methods as shown below
Call visit inside accepts method instead of super. visit, I have observed it was traversing twice if I use super hence keep this in mind
package utils;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.commons.lang3.StringUtils;
import org.apache.sling.api.resource.AbstractResourceVisitor;
import org.apache.sling.api.resource.Resource;
import org.apache.sling.api.resource.ResourceResolver;
import org.apache.sling.api.resource.ValueMap;
import com.day.cq.wcm.foundation.Image;
import com.drew.lang.annotations.NotNull;
public class ExampleResourceVisitor extends AbstractResourceVisitor {
private static final String IMAGE_RESOURCE_TYPE = "wknd/components/image";
private static final String TEXT_RESOURCE_TYPE = "wknd/components/text";
private static final ArrayList<String> ACCEPTED_PRIMARY_TYPES = new ArrayList<>();
static {
ACCEPTED_PRIMARY_TYPES.add(IMAGE_RESOURCE_TYPE);
ACCEPTED_PRIMARY_TYPES.add(TEXT_RESOURCE_TYPE);
}
private final List<String> imagepaths = new ArrayList<>();
public List<String> getImagepaths() {
return imagepaths;
}
@Override
public final void accept(final Resource resource) {
if (null != resource) {
final ValueMap properties = resource.adaptTo(ValueMap.class);
final String primaryType = properties.get(ResourceResolver.PROPERTY_RESOURCE_TYPE, StringUtils.EMPTY);
if(ACCEPTED_PRIMARY_TYPES.contains(primaryType)){
visit(resource);
}
this.traverseChildren(resource.listChildren());
}
}
@Override
protected void traverseChildren(final @NotNull Iterator<Resource> children) {
while (children.hasNext()) {
final Resource child = children.next();
accept(child);
}
}
@Override
protected void visit(@NotNull Resource resource) {
final ValueMap properties = resource.adaptTo(ValueMap.class);
final String primaryType = properties.get(ResourceResolver.PROPERTY_RESOURCE_TYPE, StringUtils.EMPTY);
if (StringUtils.equalsIgnoreCase(primaryType, IMAGE_RESOURCE_TYPE)) {
imagepaths.add(properties.get(Image.PN_REFERENCE, StringUtils.EMPTY));
}
}
}
Call the ExampleResourceVisitor and pass the resource and call the getImagepaths() to get the list of image paths
@PostConstruct
private void initModel() {
ExampleResourceVisitor exampleResourceVisitor = new ExampleResourceVisitor();
exampleResourceVisitor.accept(resource);
List < String > imageVisitorPaths = exampleResourceVisitor.getImagepaths();
}
Introduction Resource Filter Stream:
Resource Filter bundle provides a number of services and utilities to identify and filter resources in a resource tree.
Resource Filter Stream:
ResourceFilterStream combines the ResourceStream functionality with the ResourcePredicates service to provide an ability to define a Stream<Resource> that follows specific child pages and looks for specific Resources as defined by the resources filter script. The ResourceStreamFilter is accessed by adaptation.
Similar to indexing in a query there are strategies that you can do within a tree traversal so that traversals can be done in an efficient manner across a large number of resources. The following strategies will assist in traversal optimization.
Limit traversal paths
In a naive implementation of a tree traversal, the traversal occurs across all nodes in the tree regardless of the ability of the tree structure to support the nodes that are being looked for. An example of this is a tree of Page resources that has a child node of jcr:content which contains a subtree of data to define the page structure. If the jcr:content node is not capable of having a child resource of type Page and the goal of the traversal is to identify Page resources that match specific criteria then the traversal of the jcr:content node can not lead to additional matches. Using this knowledge of the resource structure, you can improve performance by adding a branch selector that prevents the traversal from proceeding down a nonproductive path
Limit memory consumption
The instantiation of a Resource object from the underlying ResourceResolver is a nontrivial consumption of memory. When the focus of a tree traversal is obtaining information from thousands of Resources, an effective method is to extract the information as part of the stream processing or utilize the forEach method of the ResourceStream object which allows the resource to be garbage collected in an efficient manner.
The article aims to address the problem of finding the best way to write a Sling servlet and the recommended way to register it in Apache Sling.
Introduction:
Servlets and scripts are themselves resources in Sling and thus have a resource path: this is either the location in the resource repository, the resource type in a servlet component configuration or the “virtual” bundle resource path (if a script is provided inside a bundle without being installed into the JCR repository).
OSGi DS – SlingServletResourceTypes
OSGi DS 1.4 (R7) component property type annotations for Sling Servlets (recommended)