Create a tool similar to AEM Operations or ACS Commons for easy access and to run any maintenance process/tasks.
Introduction:
AEM OOTB comes with multiple tools in AEM and to access all the tools you need to navigate to the tool section and select the appropriate sections to perform all the operations
For example:
AEM operations
Managing templates
Cloud configurations
ACS Commons tools etc..
Tools are an essential part of AEM and avoid any dependency on Groovy scripts or any add scripts and can be managed or extended at any given point in time.
In order to create any tool from scratch takes a lot of time and man hours and once all the configs are ready then it takes more time to develop the services and servlet to handle the business logic.
By using this tool, you can avoid all kinds of configurations and initialsetup and kick start with your own first tool from scratch
The tool generator consists of the:
Sling model – to generate fields and handle inputs
Servlet – to process request
Component – to handle view (HTL), CSS, and JS
All the above sample scratch setups along with ready to check-in code will be added to the code base.
How to use the tool?
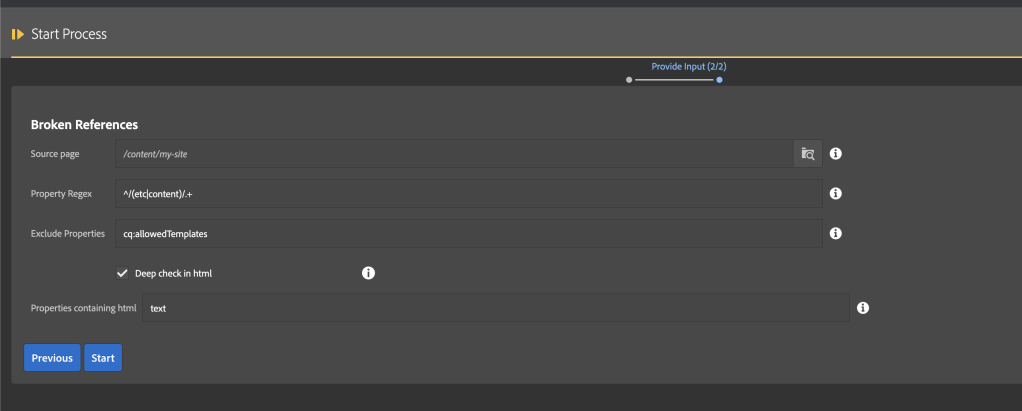
1. Click on the link to download the tool generator package and install it into your local instance
2. Once the package is installed go to sites -> tools -> and select the Tool Generator section
tool section
3. Select Tool Settings on the top right hand corner and provide your local repository paths like sling model path, servlet path, apps path, conf path, and CQ path if it already exists
tool page
4. Once all the settings are authored save the settings
tool settings
5. After coming to the generator page provide your tool name and tool description
tool authoring
6. If you have an existing tool then select Yes else Select No and provide the Tool Section name
7. Click on Create tool to create your new tool from scratch
tool result
Check your repository for all the file changes as shown below:
You can also check your new tool component and other configs on CRXDE
You can also visit your new tool by accessing the tool section (sites -> Tools -> {Your section name})
For more info on how to add a Sling model field please visit the below link:
Once your Sling model, servlet, and other things are ready make sure you add the following filter in your META-INF folder and keep it merge as shown below:
This would avoid replacing/overriding any other tools like ACS Commons or your other repo tools.
Get a List of all the Assets which are missing references
Requirement:
Get the list of broken asset references to unpublish and remove them repo to improve the system stability and performance.
Introduction:
How do assets get published?
The author uploads the images and publishes the assets
Create a launcher and workflow which process assets metadata and publish the pages
Whenever we publish any pages and if the page has references to assets, then during publishing, it asks to replicate the references as well.
What happens when the page is unpublished?
When the page is deactivated, assets referenced to the page will not be deactivated because this asset might have reference to the other pages hence out of the box assets won’t be deactivated.
If we perform cleanup, deactivate and delete old pages, we might not be cleaning up assets related to this page.
Advantages of cleaning up old assets?
Drastically reduces repository size
Improves DAM Asset search
Improves indexing
Get Publish Report using Assets Report:
Go to Tools -> Assets -> Reports as shown below:
Asset Reports
Click on create and click on Publish report
Select Publish report
Provide folder path and start date and end date
Add Report details
Select the columns as per requirement
Configure columns for the report
Finally, report will be ready with all the assets lists as shown below
Completed Reports
Download the report to see the final list of images
Example Report CSV file
If Images are unpublished then we can ask authors to review and delete them
If images are published but has no references to figure this out, we need a new process.
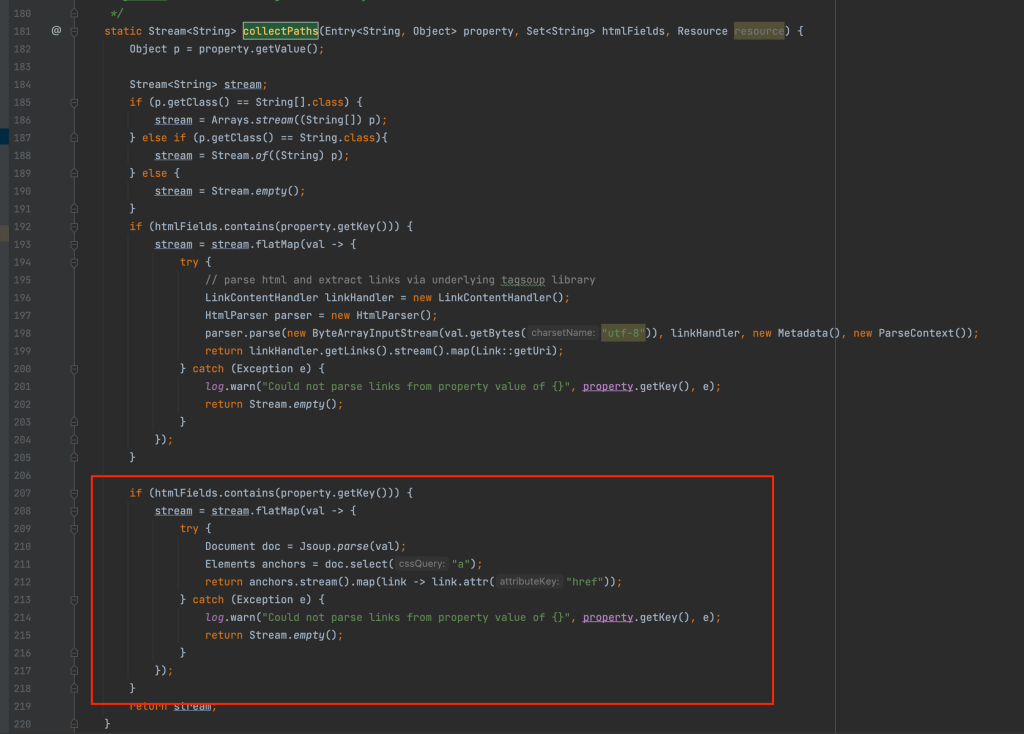
MCP (Manage Controlled Processes) is both a dashboard for performing complex tasks and a rich API for defining these tasks as process definitions. In addition to kicking off new processes, users can also monitor running tasks, retrieve information about completed tasks, halt work, and so on.
Add the following maven dependency to your pom to extend MCP
After building the code you can see the new Process showing up in MCP
Borken Asset Refernce Process
Copy the Path column into the new Excel sheet as shown below
Path column into new excel file
Upload into the process and start to see all the images which are published yet unreferenced as shown below
Why does Chunk count?
Chunk count helps the SQL 2 query to group by the paths, which will be maxing 4500 and it won’t take more than that (configurable based on the environment). However basically, if we have 20000 / 4500 = 4.44 ~ 5 we will be running the query max five times to generate the below report
Share the report with the content authors team to validate if images are required if not plan to clean up using
After completing the processExample report and we can download and share with Authors
Clean up Process:
Authors don’t have to unpublish and delete individual images, then can you use the below process to upload the excel sheet with all the approved image paths and upload it to the process to deactivate and delete