Problem Statement:
How to set up an AEM instance in one click?
Can I perform incremental builds on the Maven project?
Introduction:
Gradle AEM Plugin (GAP) developed by Wunderman Thompson Technology uses Gradle as a building tool.
Advantages of Gradle:
1. Flexibility
2. Performance
- Incrementality — tracks the tasks, watches file changes and runs only what is necessary.
- Build Cache — Reuses the build outputs of any other Gradle build with the same inputs.
- Gradle Daemon — A long-lived process that keeps building information “hot” in memory.
3. User experience
How to get started?
Step 1: Create the project outside the Desktop, Documents and Downloads folder to avoid all kinds of setup issues.
Step 2: Create a new project structure using an AEM archetype (using the latest archetype of the below example) you can also run on your current project if it follows the Adobe archetype:

Step 3: Run the following command to integrate AEM archetype with GAP:
curl -OJL https://github.com/Cognifide/gradle-aem-plugin/releases/download/16.0.7/gap.jar && java -jar gap.jar && rm gap.jar
Step 4: Provide AEM Jar and license details and other configurations:
sh gradlew config
- Provide JAR Path
- License Path
- Service Pack path (AEM On-premise, AEM6.5)
- Core components path

Step 5: Run the following command to start the new environment:
sh gradlew :env:setup
Or
sh gradlew


Step 6: Run the following command to deploy the code into your local instance:
sh gradlew :all:packageDeploy


Step 7: To stop the environment, you can use the following command:
sh gradlew down
Step 8: To start the environment, you can use the following command:
sh gradlew up
Issues:
- If you have multiple project repos, then it’s hard to maintain multiple instances of AEM.
- If you have dependency between repos, then incremental build might fail.
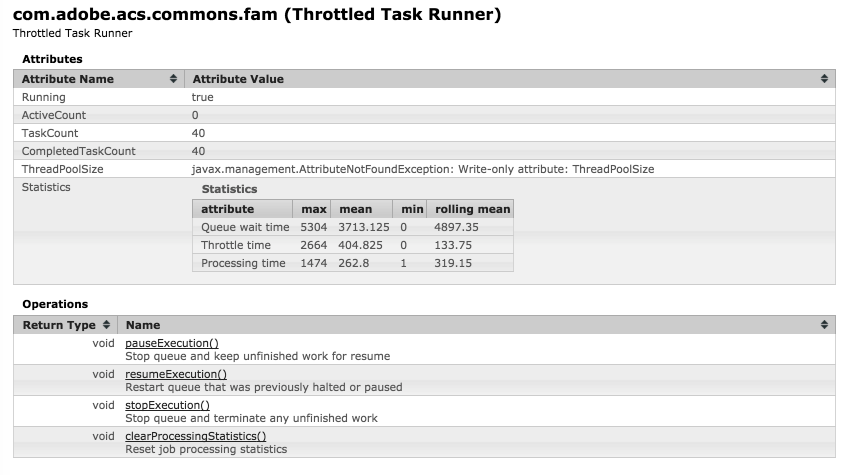
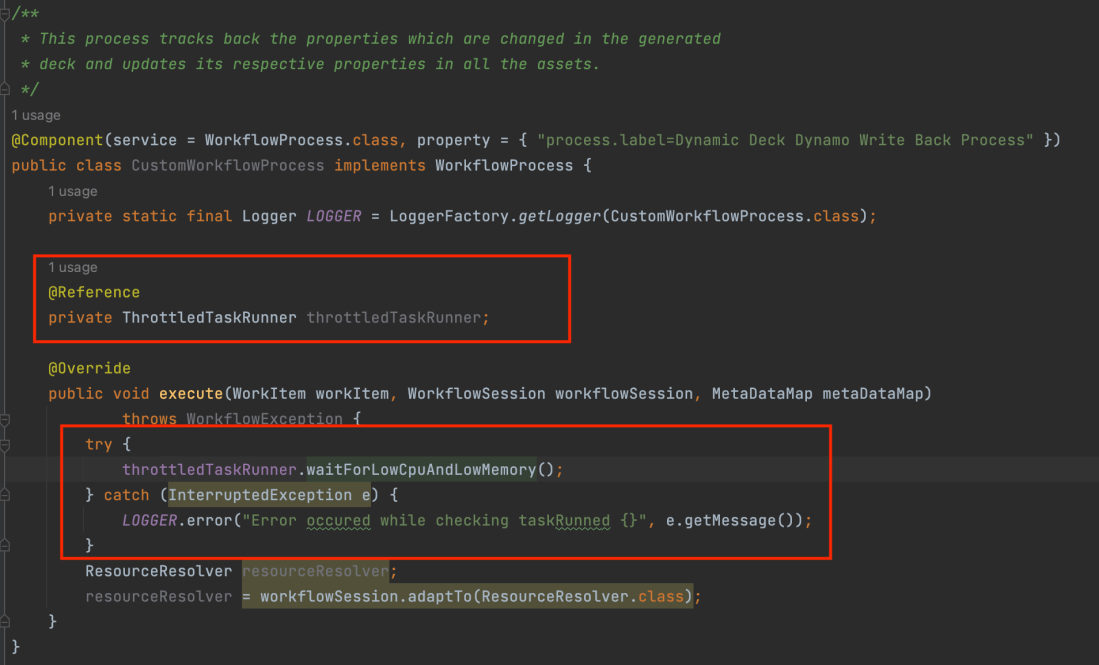
- If you have installed ACS Commons and if live to reload the bundle or any bundles are in the installed state, then deploy might hang during the bundle stability check.
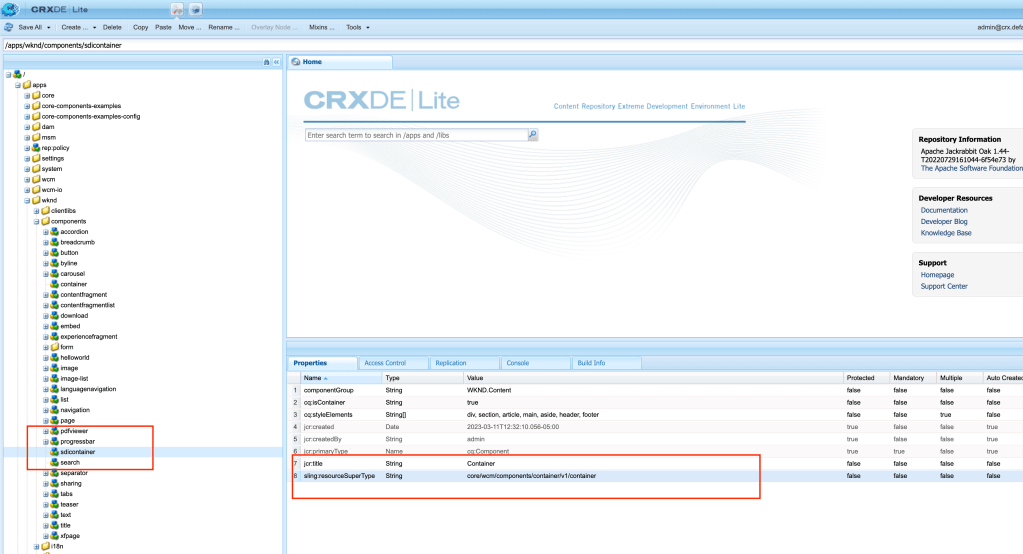
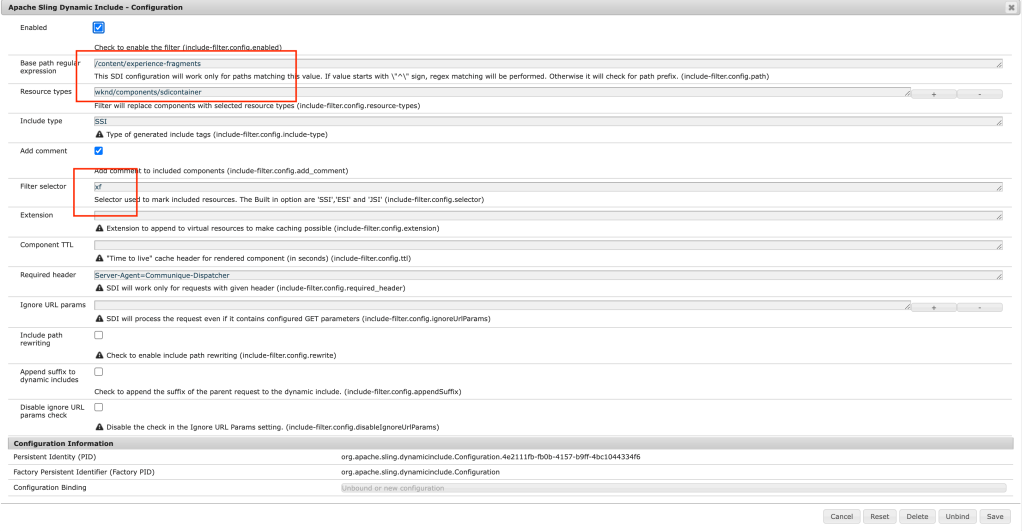
For more information on GAP plugin please visit the following documentation: