Problem statement:
How to improve the authoring experience in AEM using SDI?
Can I optimize page load time?
Can I cache all experience fragments on the pages in AEM?
Introduction:
The purpose of the module presented here is to replace dynamically generated components (eg. current time or foreign exchange rates) with server-side include tags (eg. SSI or ESI). Therefore, the dispatcher is able to cache the whole page but dynamic components are generated and included with every request. Components to include are chosen in filter configuration using resourceType attribute.
When the filter intercepts a request for a component with a given resourceType, it’ll return a server-side include tag (eg. <!–#include virtual=”/path/to/resource” –> for the Apache server). However, the path is extended by a new selector (XF by default). This is required because the filter has to know when to return actual content.
Before going through this article please visit my other blog on Cache Experience Fragments in AEM Using Sling Dynamic Include all the simple customization to cache call the experience fragments on the page to improve page load time on published pages.
Flow diagram on the approach:
As part of this implementation, we are trying to cache all the experience fragments at different paths like /mnt/var/www/author/content/experience-fragment/{site-structure} as shown below:

If SDI is enabled on the author:
- On the local author instance all the experience fragments might disappear if the author instance is accessed on the local dispatcher or any lower environments as shown below:

- After accessing the page on the dispatcher attached to the author the experience fragment might be broken and it would allow the components on the experience fragment can be authored directly from the page (kind of new feature) but it would break if any permissions of authoring on header/footer etc.

Override the wrapper component:
If it is a Layout container, then please override the responsivegrid.html by copying responsivegrid.html from wcm/foundation/components/responsivegrid the as shown below:
<sly data-sly-test="${wcmmode.edit}" data-sly-use.allowed="com.day.cq.wcm.foundation.model.AllowedComponents"></sly>
<div data-sly-use.api="com.day.cq.wcm.foundation.model.responsivegrid.ResponsiveGrid" class="${api.cssClass} ${allowed.cssClass}">
<sly data-sly-test.isAllowedApplicable="${allowed.isApplicable}"
data-sly-test="${isAllowedApplicable}"
data-sly-use.allowedTemplate="/libs/wcm/foundation/components/parsys/allowedcomponents/allowedcomponents-tpl.html"
data-sly-call="${allowedTemplate.allowedcomponents @ title=allowed.title, resourcesMap=allowed.resourcesMap,
placeholderCss=allowed.placeholderCssClass,
placeholderType=allowed.placeholderResourceType}"></sly>
<sly data-sly-test="${!isAllowedApplicable}"
data-sly-repeat.child="${api.paragraphs}"
data-sly-resource="${child.resource @ decoration='true', cssClassName=child.cssClass, wcmmode='disabled'}"></sly>
<sly data-sly-test="${!isAllowedApplicable && !wcmmode.disabled}"
data-sly-resource="${resource.path @ resourceType='wcm/foundation/components/responsivegrid/new', appendPath='/*', decorationTagName='div', cssClassName='new section aem-Grid-newComponent'}"/>
</div>

If it is a Core Container component please override the responsivegrid.html and allowedcomponents.html by copying responsivegrid.html and allowedcomponents.html from core/wcm/components/container and the as shown below:
<template data-sly-template.responsiveGrid="${ @ container}">
<div id="${container.id}"
class="cmp-container"
aria-label="${container.accessibilityLabel}"
role="${container.roleAttribute}"
style="${container.backgroundStyle @ context='styleString'}">
<sly data-sly-resource="${resource @ resourceType='wcm/foundation/components/responsivegrid', wcmmode='disabled'}"></sly>
</div>
</template>
<template data-sly-template.allowedcomponents="${@ title, components}">
<div data-text="${title}"
class="aem-AllowedComponent--title"></div>
<sly data-sly-repeat.comp="${components}"
data-sly-resource="${comp.path @ resourceType=comp.resourceType, decorationTagName='div', cssClassName=comp.cssClass, wcmmode='disabled'}"></sly>
</template>


With the above fix, the experience fragment component won’t break and won’t be authorable on the page and works as expected.

What about the experience fragment page? It’s not authorable, because of the wcmmode=’disabled’ parameter in sightly

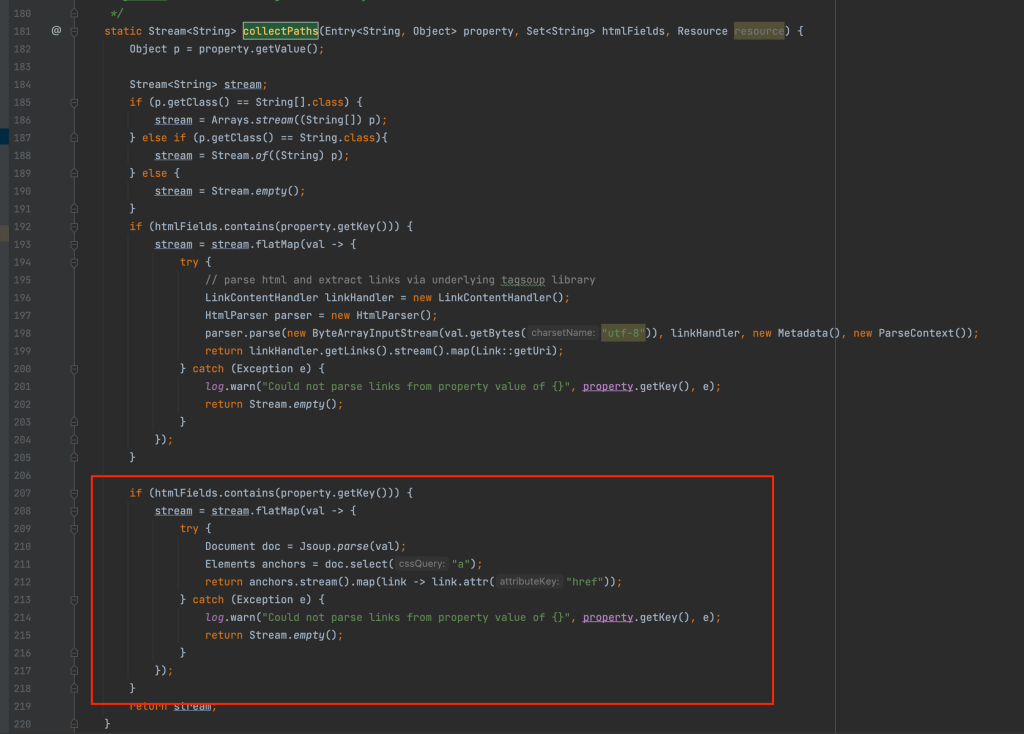
To fix the above issue Create a sling model as shown below:
This model class replaces the wrapper component with Synthetic Resource pointing to the layout container or core container component, which will avoid SDI picking based on the resourcetype
package com.adobe.aem.guides.wknd.core.models;
import com.adobe.granite.ui.components.ds.ValueMapResource;
import org.apache.sling.api.SlingHttpServletRequest;
import org.apache.sling.api.resource.Resource;
import org.apache.sling.api.resource.ResourceResolver;
import org.apache.sling.api.resource.ValueMap;
import org.apache.sling.api.wrappers.ValueMapDecorator;
import org.apache.sling.models.annotations.DefaultInjectionStrategy;
import org.apache.sling.models.annotations.Model;
import org.apache.sling.models.annotations.injectorspecific.RequestAttribute;
import org.apache.sling.models.annotations.injectorspecific.SlingObject;
import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
@Model(adaptables = SlingHttpServletRequest.class, defaultInjectionStrategy = DefaultInjectionStrategy.OPTIONAL)
public class ExperienceFragmentModel {
private static final String SDI_COMPONENT_RESOURCETYPE = "wknd/components/sdicontainer";
private static final String RESPONSIVE_COMPONENT_RESOURCETYPE = "core/wcm/components/container/v1/container";
@SlingObject
private ResourceResolver resourceResolver;
@RequestAttribute
private List<Resource> structureResources;
List<Resource> structuredResource = new ArrayList<>();
@PostConstruct
private void initModel() {
if(!structureResources.isEmpty() && structureResources.size() == 1) {
Resource rootRes = structureResources.get(0);
if(null != rootRes && rootRes.hasChildren()) {
Resource responsiveRes = rootRes.getChildren().iterator().next();
if(responsiveRes.isResourceType(SDI_COMPONENT_RESOURCETYPE)) {
structuredResource.add(createSyntheticResource(responsiveRes));
} else {
structuredResource = structureResources;
}
} else {
structuredResource = structureResources;
}
} else {
structuredResource = structureResources;
}
}
public List<Resource> getStructuredResource() {
return structuredResource;
}
private Resource createSyntheticResource(Resource childResource) {
ValueMap properties = new ValueMapDecorator(new HashMap<>());
Resource sdiComponentResource = new ValueMapResource(resourceResolver, childResource.getPath(), RESPONSIVE_COMPONENT_RESOURCETYPE, properties);
return sdiComponentResource;
}
}
Override body.html by copying the body.html from cq/experience-fragments/components/xfpage of the experience fragment page component and add the following code:
<sly data-sly-use.body="body.js" data-sly-use.templatedContainer="com.day.cq.wcm.foundation.TemplatedContainer"/>
<sly data-sly-test="${!templatedContainer.hasStructureSupport}"
data-sly-resource="${body.resourcePath @ resourceType='wcm/foundation/components/parsys'}"/>
<div class="container">
<sly data-sly-test="${templatedContainer.hasStructureSupport}"
data-sly-use.rootChild="${'com.adobe.aem.guides.wknd.core.models.ExperienceFragmentModel' @structureResources=templatedContainer.structureResources }"
data-sly-repeat.child="${rootChild.structuredResource}"
data-sly-resource="${child.path @ resourceType=child.resourceType, decorationTagName='div'}"/>
</div>
<div data-sly-resource="${'cloudservices' @ resourceType='cq/cloudserviceconfigs/components/servicecomponents'}"
data-sly-unwrap></div>
<sly data-sly-include="footerlibs.html"/>

Finally, with the above fix, the experience fragment page is editable, and SDI include statement will disappear on the experience fragment page.
To clear the cache you need to add /author/content/{experience-fragment} path to acs commons dispatcher cache clear path
Advantages of caching Experience fragment at common or shared location:
- Increases initial page load – response time based on the number of XF on the page
- Improves overall page load time
- Better debugging SDI functionality – whenever the XF page is updated and published it removes from the cache and on a new page request a new cache is created and used on subsequent requests
- Decreases CPU utilization